Java HashMap LinkedHashMapHashMap是Map族中最为常用的一种,也是Java Collection Framework的重要成员。HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Node节点链入一个双向链表的HashMap。下面基于JDK 1.8的源码来学习HashMap及LinkedHashMap的数据结构、原理。不同JDK版本之间也许会有些许差异,但不影响原理学习,JDK8相比以前对HashMap的修改比较大。
1、HashMap概述
Map是 Key-Value键值对映射的抽象接口,该映射不包括重复的键,即一个键对应一个值。HashMap是Java Collection Framework的重要成员,也是Map族(如下图所示)中最为常用的一种。简单地说,HashMap是基于哈希表的Map接口的实现,以Key-Value的形式存在,即存储的对象是 Node (同时包含了Key和Value) 。在HashMap中,其会根据hash算法来计算key-value的存储位置并进行快速存取。特别地,HashMap最多只允许一条Node的key为Null,但允许多条Node的value为Null。此外,HashMap是Map 的一个非同步的实现。以下是HashMap的类继承图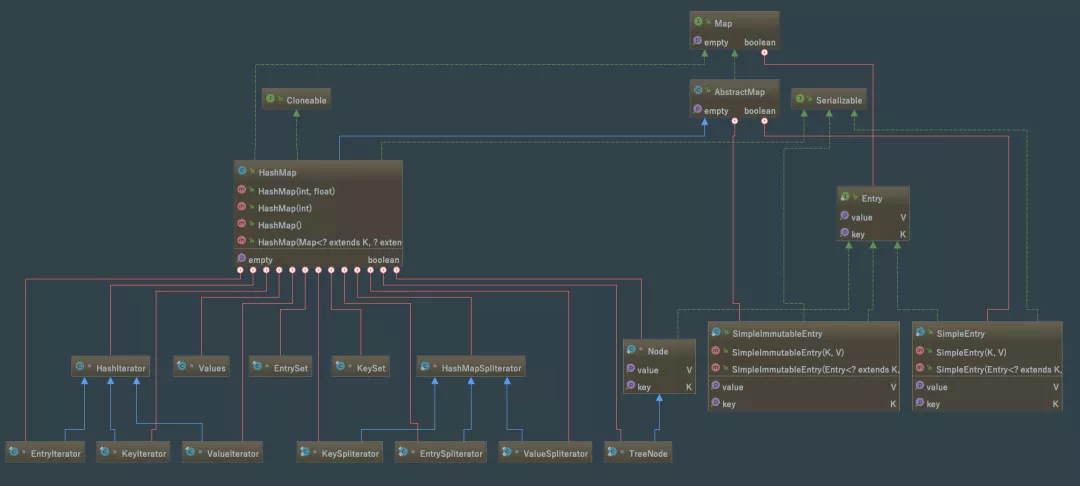 必须指出的是,虽然容器号称存储的是%20Java%20对象,但实际上并不会真正将%20Java%20对象放入容器中,只是在容器中保留这些对象的引用。也就是说,Java%20容器实际上包含的是引用变量,而这些引用变量指向了要实际保存的%20Java%20对象。
必须指出的是,虽然容器号称存储的是%20Java%20对象,但实际上并不会真正将%20Java%20对象放入容器中,只是在容器中保留这些对象的引用。也就是说,Java%20容器实际上包含的是引用变量,而这些引用变量指向了要实际保存的%20Java%20对象。
1.1、HashMap定义及构造函数JDK中的定义为
public%20class%20HashMap<K,V>%20extends%20AbstractMap<K,V>%20implements%20Map<K,V>,%20Cloneable,%20Serializable%20{%20%20%20%20//...}
HashMap%20一共提供了四个构造函数,其中%20默认无参的构造函数%20和%20参数为Map的构造函数%20为%20Java%20Collection%20Framework%20规范的推荐实现,其余两个构造函数则是%20HashMap%20专门提供的。
public%20HashMap(int%20initialCapacity)%20{%20%20%20%20this(initialCapacity,%20DEFAULT_LOAD_FACTOR);}//仅仅将负载因子初始化为默认值public%20HashMap()%20{%20%20%20%20this.loadFactor%20=%20DEFAULT_LOAD_FACTOR;%20%20%20%20%20//%20all%20other%20fields%20defaulted}
HashMap(int%20initialCapacity,%20float%20loadFactor)构造函数意在构造一个指定初始容量和指定负载因子的空HashMap,其源码如下:
public%20HashMap(int%20initialCapacity,%20float%20loadFactor)%20{%20%20%20%20if%20(initialCapacity%20<%200)%20%20%20%20%20%20%20%20throw%20new%20IllegalArgumentException("Illegal%20initial%20capacity:%20"%20+%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20initialCapacity);%20%20%20%20//容量最大为2的30次方%20%20%20%20if%20(initialCapacity%20>%20MAXIMUM_CAPACITY)%20%20%20%20%20%20%20%20initialCapacity%20=%20MAXIMUM_CAPACITY;%20%20%20%20if%20(loadFactor%20<=%200%20||%20Float.isNaN(loadFactor))%20%20%20%20%20%20%20%20throw%20new%20IllegalArgumentException("Illegal%20load%20factor:%20"%20+%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20loadFactor);%20%20%20%20this.loadFactor%20=%20loadFactor;%20%20%20%20//这里调用函数计算触发扩容的阈值,threshold/loadFactor就是容量%20%20%20%20this.threshold%20=%20tableSizeFor(initialCapacity);}
以上构造函数的最后一行就是jdk8的修改,实际上在jdk7之前的版本,这个构造方法最后一行就是:
table%20=%20new%20Entry[capacity];
但是jdk8的最后一行并没有立刻new出一个数组,而是调用了tableSizeFor方法,将结果赋值给了threshold变量。tableSizeFor方法源码如下,从注释就可以看出来,其目的是要获得大于cap的最小的2的幂。比如cap=10,则返回16。
/** 

评论