Java HashMap
JDK7 的HashMap
先说 JDK7 中的 HashMap 的数据结构,然后再去看 JDK8 中的 HashMap的数据结构.都知道 JDK7 中的 HashMap 的数据结构是一个数组加上链表的形式,也就是下面这副图,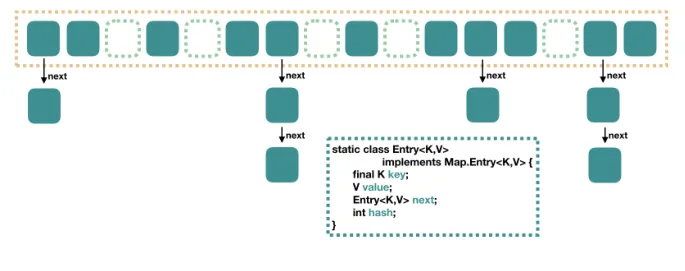 也就是说相当于从左到右,HashMap%20就相当于一个数组,而数组中每个元素是一个单向链表,图中的横向的每一个绿色的方块都表示%20Entry,Entry%20包含四个属性:key,%20value,%20hash%20值还有用于单向链表的%20next。
也就是说相当于从左到右,HashMap%20就相当于一个数组,而数组中每个元素是一个单向链表,图中的横向的每一个绿色的方块都表示%20Entry,Entry%20包含四个属性:key,%20value,%20hash%20值还有用于单向链表的%20next。
static%20final%20int%20DEFAULT_INITIAL_CAPACITY%20=%2016;static%20final%20float%20DEFAULT_LOAD_FACTOR%20=%200.75F;int%20threshold;final%20float%20loadFactor;static%20class%20Entry<K,%20V>%20implements%20java.util.Map.Entry<K,%20V>%20{%20%20%20%20final%20K%20key;%20%20%20%20V%20value;%20%20%20%20HashMap.Entry<K,%20V>%20next;%20%20%20%20int%20hash;%20%20%20%20Entry(int%20var1,%20K%20var2,%20V%20var3,%20HashMap.Entry<K,%20V>%20var4)%20{%20%20%20%20%20%20%20%20this.value%20=%20var3;%20%20%20%20%20%20%20%20this.next%20=%20var4;%20%20%20%20%20%20%20%20this.key%20=%20var2;%20%20%20%20%20%20%20%20this.hash%20=%20var1;%20%20%20%20}}
其实如果对比%20JDK7%20和JDK8%20的源码的话,差距不小呢,改动也算是挺大的改动了,CAPACITY:%20当前数组容量,始终保持%202^n,可以扩容,扩容后数组大小为当前的%202%20倍loadFactor:%20负载因子,默认为%200.75threshold:%20扩容的阈值,等于%20capacity%20*%20loadFactor这时候,HashMap%20其实可以看成一种懒加载的方式,当没有数据%20put%20进来的时候,是不会创建数组的。当进行put的时候,数据插入到%20HashMap%20中,
JDK8%20的HashMapJava8%20对%20HashMap%20进行了一些修改,最大的不同就是利用了红黑树,所以其由%20数组+链表+红黑%20树组成。就像下面的图:
public%20HashMap(int%20initialCapacity,%20float%20loadFactor)%20{%20%20%20%20if%20(initialCapacity%20<%200)%20%20%20%20%20%20%20%20throw%20new%20IllegalArgumentException("Illegal%20initial%20capacity:%20"%20+%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20initialCapacity);%20%20%20%20if%20(initialCapacity%20>%20MAXIMUM_CAPACITY)%20%20%20%20%20%20%20%20initialCapacity%20=%20MAXIMUM_CAPACITY;%20%20%20%20if%20(loadFactor%20<=%200%20||%20Float. 

评论