

文章总结: 中科院与南洋理工大学提出AURA框架,通过在知识图谱注入虚假数据防范窃取。该框架利用最小顶点覆盖算法和混合生成策略,使盗版数据失效且难检测,授权用户可过滤污染物。测试表明其能有效规避检测与净化,降低被盗模型推理精度,为GraphRAG知识产权保护提供了解决方案。 综合评分: 88 文章分类: AI安全,数据安全,解决方案
AURA创新框架自动化数据投毒方案应对AI模型窃取威胁
FreeBuf
2026年1月8日 18:31 上海
中国科学院与南洋理工大学的研究团队近日提出名为AURA的创新框架,旨在保护GraphRAG系统中的专有知识图谱免遭窃取和非法利用。这篇一周前发表于arXiv的论文指出,通过在知识图谱中混入看似合理但虚假的数据,可使被盗副本对攻击者失效,同时确保授权用户仍能完整使用。
Part01
知识图谱的价值与风险
知识图谱支撑着从辉瑞药物研发到西门子制造等众多GraphRAG高级应用,存储着价值数百万美元的知识产权。现实中的数据泄露事件凸显了风险:2018年Waymo工程师窃取14,000份激光雷达文件,2020年黑客通过欧洲药品管理局攻击辉瑞-生物新技术疫苗数据。
攻击者窃取知识图谱是为了私下复制GraphRAG功能,规避需要输出访问权限的数字水印技术,而加密技术又会降低低延迟查询效率。传统防御手段在攻击者离线操作的”私人使用”场景中失效。尽管欧盟《人工智能法案》和美国国家标准与技术研究院(NIST)框架都强调数据韧性,但目前尚无解决方案填补这一空白。
Part02
ARUR的数据污染策略
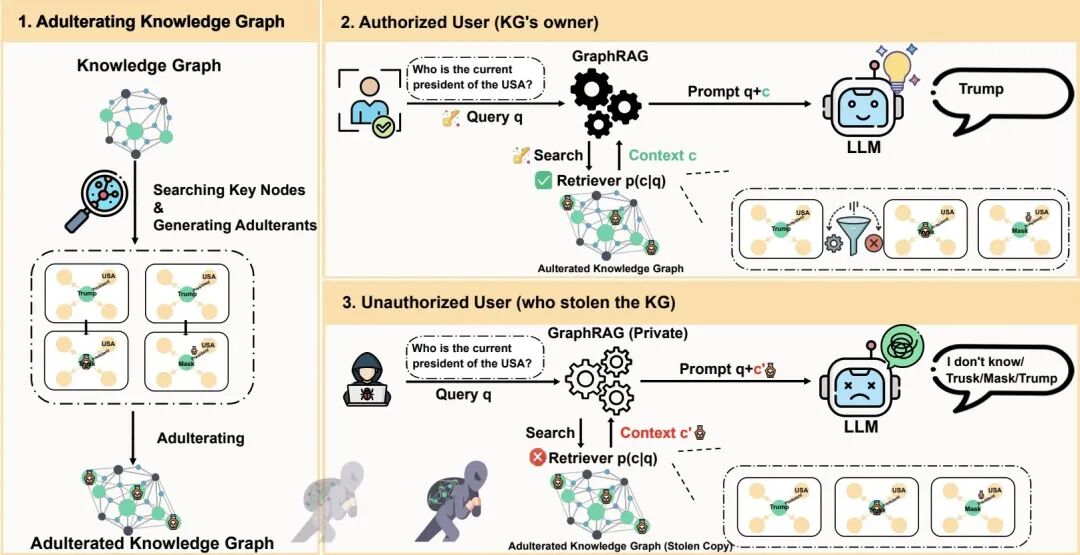
AURA从预防转向价值破坏策略:向关键知识图谱节点注入”污染物”——模仿真实数据的虚假三元组。通过最小顶点覆盖(MVC)算法选择关键节点,对小规模图谱使用整数线性规划(ILP)求解,对大规模图谱则采用Malatya启发式算法,确保以最小改动覆盖所有边。
污染物结合了链接预测模型(TransE、RotatE)的结构合理性和大语言模型(LLM)的语义连贯性。基于语义偏差分数(SDS)的句子嵌入欧氏距离进行影响驱动选择,为每个节点挑选最具破坏性的污染物。加密的AES元数据标记(作为”remark”属性)允许授权系统在检索后使用密钥进行过滤,实现可证明的IND-CPA安全性。
Part03
测试结果与性能表现
在MetaQA、WebQSP、FB15k-237和HotpotQA数据集上,使用GPT-4o、Gemini-2.5-flash和Llama2-7B等模型的测试显示:
污染物成功规避了检测系统(ODDBALL:4.1%,Node2Vec:3.3%)和净化处理(SEKA:94.5%保留率,KGE:80.2%)。在多跳推理中,有害分数持续上升(3跳时达95.8%),在各类检索器和微软GraphRAG等先进框架中均表现稳健。
消融研究证实了混合生成方法的优势:纯LLM方法易受结构检查影响,而纯链接预测方法则存在语义问题。即使每个节点仅注入一个污染物,也能获得超过94%的高分;额外污染物仅带来边际收益。
Part04
局限性与应用前景
当前局限包括未处理节点上的文本描述和内部蒸馏风险,可通过API控制缓解。AURA开创了知识图谱知识产权保护的”主动降级”方法,区别于攻击性污染(PoisonedRAG、TKPA)或被动水印(RAG-WM)。随着GraphRAG技术普及,微软、谷歌和阿里巴巴等企业正加大投入,以应对AI时代的数据窃取威胁。
参考来源:
Researchers Manipulate Stolen Data to Corrupt AI Models and Generate Inaccurate Outputs
Researchers Manipulate Stolen Data to Corrupt AI Models and Generate Inaccurate Outputs
#
#
#
推荐阅读
#
电台讨论
免责声明:
本文所载程序、技术方法仅面向合法合规的安全研究与教学场景,旨在提升网络安全防护能力,具有明确的技术研究属性。
任何单位或个人未经授权,将本文内容用于攻击、破坏等非法用途的,由此引发的全部法律责任、民事赔偿及连带责任,均由行为人独立承担,本站不承担任何连带责任。
本站内容均为技术交流与知识分享目的发布,若存在版权侵权或其他异议,请通过邮件联系处理,具体联系方式可点击页面上方的联系我。
本文转载自:FreeBuf 《AURA创新框架自动化数据投毒方案应对AI模型窃取威胁》

版权声明
本站仅做备份收录,仅供研究与教学参考之用。
读者将信息用于其他用途的,全部法律及连带责任由读者自行承担,本站不承担任何责任。









评论