

Java 线程池在遇到一些单线程处理很慢的场景,往往会采用多线程的方式进行处理,从而缩短处理时间提升性能。往往这个时候就会想到 Java 中JUC 包中提供的线程池创建方法,如下所示,通过 JDK 自带的 Executors 类中的几个静态方法,创建需要的线程池,再通过 ExecutorService 的带返回值的 submit() 或者 不带返回值的 execute() 方式来异步处理业务逻辑。
ExecutorService executorService0 = Executors.newFixedThreadPool(10);ExecutorService executorService1 = Executors.newSingleThreadExecutor();ExecutorService executorService2 = Executors.newCachedThreadPool();Future<?> submit = executorService0.submit(new Runnable() {@Overridepublic void run() {}});executorService.execute(new Runnable() {@Overridepublic void run() {}});
代码写到了这里,普通程序员都觉得应该已经结束了,剩下的就交给线程池就好了,不过稍微优秀一点的程序员会觉得有点不妥,知道应该再根据业务逻辑情况以及服务器的配置,进行线程数的配置,设置合理的线程数。比如这里设置的是 10,可以根据自身的情况进行相应的配置。大部分程序员到这一步就真的觉得应该结束了,该设置的也设置了,接下来就让线程池按照配置好好运行,一切都很完美。然后事情并没有想象的那么美好,有时候发现在高峰期的时候,偶尔会 OOM 内存溢出的情况,那为什么这个逻辑会出现 OOM 呢?
Executor是不建议的
只要看过线程池源码的同学都知道,Executors类提供了各种类型的线程池,经常使用的工厂方法有:
public static ExecutorService newSingleThreadExecutor()public static ExecutorService newFixedThreadPool(int nThreads)public static ExecutorService newCachedThreadPool()public static ScheduledExecutorService newSingleThreadScheduledExecutor()public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
不管是 Executors.newFixedThreadPool() ,Executors.newSingleThreadExecutor() 还是 Executors.newCachedThreadPool(),底层的实现都是通过构造 ThreadPoolExecutor 这个类来实现了,不同的地方只是具体参数的不同而已。如下所示单个线程: Executors.newSingleThreadExecutor();
public static ExecutorService newSingleThreadExecutor() {returnnew FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
缓存线程:Executors.newCachedThreadPool();
public static ExecutorService newCachedThreadPool() {returnnew ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
固定线程Executors.newFixedThreadPool(2);
public static ExecutorService newFixedThreadPool(int nThreads) {returnnew ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
定时线程: Executors.newScheduledThreadPool(3);(父类中)
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);}
通过这几个静态方法对应的构造实现,可以发现 newSingleThreadExecutor() 和 newFixedThreadPool()中的消息队列的长度为 Integer.MAX_VALUE,而 newCachedThreadPool() 方法允许创建的最大线程数为 Integer.MAX_VALUE。这些固定的静态方法的默认配置有很大的问题!队列长度太长在高峰期的时候会堆积大量的请求,从而产生 OOM,而创建大量的线程也是一个道理,会把服务器的资源消耗殆尽,从而也产生 OOM!书写一段很简单的测试代码:
public class ThreadDemo {public static void main(String[] args) {ExecutorService es = Executors.newSingleThreadExecutor();}}
当用阿里巴巴的P3C检查代码时,会被教育的!!!!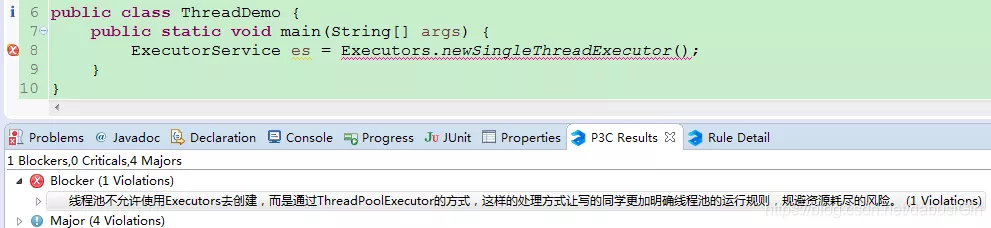 阿里规约是不允许这么创建线程池的,上面的警告写的很明确“线程池不允许使用Executors去创建,而是通过
阿里规约是不允许这么创建线程池的,上面的警告写的很明确“线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。”
强制使用ThreadPoolExecutor
使用ThreadPoolExecutor创建线程池:
public class ThreadDemo {public static void main(String[] args) {ExecutorService es = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(10), Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardPolicy());}}
此时,再用P3C检查代码,终于没有报错了。还是有必要从JDK源码的层面深挖一下其中的原理。首先是静态方法newSingleThreadExecutor()、newFixedThreadPool(int nThreads)、newCachedThreadPool()。来看一下其源码实现(基于JDK8)。
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
通过查看源码可以知道上述三种静态方法的内部实现均使用了ThreadPoolExecutor类。难怪阿里建议通过ThreadPoolExecutor的方式实现,原来Executors类的静态方法也是用的它,只不过配了一些参数而已。第二是ThreadPoolExecutor类的构造方法。既然现在要直接使用ThreadPoolExecutor类了,那么其中的初始化参数就要自己配了,了解其构造方法势在必行。ThreadPoolExecutor类一共有四个构造方法,只需要了解之中的一个就可以了,因为其他三种构造方法只是配置了一些默认参数,最后还是调用了它。
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
其中的参数含义是:
corePoolSize:线程池中的线程数量;maximumPoolSize:线程池中的最大线程数量;keepAliveTime:当线程池线程数量超过corePoolSize时,多余的空闲线程会在多长时间内被销毁;unit:keepAliveTime的时间单位;workQueue:任务队列,被提交但是尚未被执行的任务;threadFactory:线程工厂,用于创建线程,一般情况下使用默认的,即Executors类的静态方法defaultThreadFactory();handler:拒绝策略。当任务太多来不及处理时,如何拒绝任务。
corePoolSize与maximumPoolSize的关系
首先corePoolSize肯定是 <= maximumPoolSize。其他关系如下:
- 若
当前线程池中线程数 < corePoolSize,则每来一个任务就创建一个线程去执行; - 若
当前线程池中线程数 >= corePoolSize,会尝试将任务添加到任务队列。如果添加成功,则任务会等待空闲线程将其取出并执行; - 若队列已满,且
当前线程池中线程数 < maximumPoolSize,创建新的线程; - 若
当前线程池中线程数 >= maximumPoolSize,则会采用拒绝策略(JDK提供了四种,下面会介绍到)。
注意:关系3是针对的有界队列,无界队列永远都不会满,所以只有前2种关系。
workQueue
参数workQueue是指提交但未执行的任务队列。若当前线程池中线程数>=corePoolSize时,就会尝试将任务添加到任务队列中。主要有以下几种:
SynchronousQueue:直接提交队列。SynchronousQueue没有容量,所以实际上提交的任务不会被添加到任务队列,总是将新任务提交给线程执行,如果没有空闲的线程,则尝试创建新的线程,如果线程数量已经达到最大值(maximumPoolSize),则执行拒绝策略。LinkedBlockingQueue:无界的任务队列。当有新的任务来到时,若系统的线程数小于corePoolSize,线程池会创建新的线程执行任务;当系统的线程数量等于corePoolSize后,因为是无界的任务队列,总是能成功将任务添加到任务队列中,所以线程数量不再增加。若任务创建的速度远大于任务处理的速度,无界队列会快速增长,直到内存耗尽。handlerJDK内置了四种拒绝策略:
DiscardOldestPolicy策略:丢弃任务队列中最早添加的任务,并尝试提交当前任务;CallerRunsPolicy策略:调用主线程执行被拒绝的任务,这提供了一种简单的反馈控制机制,将降低新任务的提交速度。DiscardPolicy策略:默默丢弃无法处理的任务,不予任何处理。AbortPolicy策略:直接抛出异常,阻止系统正常工作。
至此,直接new ThreadPoolExecutor类就不用慌了!

版权声明
本站仅做备份收录,仅供研究与教学参考之用。
读者将信息用于其他用途的,全部法律及连带责任由读者自行承担,本站不承担任何责任。







评论