

文章总结: 本文介绍了如何利用5个Agent搭建一条内容自动生产线,以实现自媒体内容的全自动化生产。该系统将内容创作流程拆分为选题、写作、发布、数据分析和总编调度五个环节,各由一个专职Agent负责。其中,Scout负责从138个信息源中扫描并筛选选题;Writer通过七道工序对AI生成的初稿进行去AI腔审校、多轮修订和配图排版;Publisher使用Playwright模拟人工操作浏览器,将内容安全地发布至草稿箱;Feedback则自动回收数据,反哺选题策略以优化后续内容;最后通过Dashboard可视化整个流程。该方案极大提升了内容生产效率,将每日工作时间从5小时缩短至5分钟。
综合评分: 85
文章分类: 解决方案,技术标准,产品介绍,AI安全,其他
我用Hermes通过5个Agent搭了一条内容自动生产线, 现在每天能发13篇, 极大的提高了创效率
原创
一人AI马特啦 一人AI马特啦
一人AI马特啦
2026年5月5日 23:46 广东
在小说阅读器读本章
去阅读
凌晨5:59,手机震了一下。
微信弹出通知——「07:00 内容已就绪」。
我没睁眼。等到7:30醒来才看:一篇深度文章,两篇微头条,标题配图排版全齐了。
其实早在7:04,就推送到toutiao草稿箱了。(其实也可以直接发布,但是我认为最后一步人要in-loop, 去确认你要发布的内容,对自己和读者负责,所以只让Hermes推送到草稿箱)
就这样我的这个测试项目就跑通了😄
这不是在说未来。这是我这个五一用Hermes搭建的toutiao自动化生产线。现在我每天可以收到13篇内容(4篇长文+9篇微头条)推送,分早7点、中午12点、晚6点、晚9点四个时间段发到头条号。
选题、写作、配图、发布、数据回收,AI全干了。
我每天的工作就是去确认后发布。
为什么要做这个
我最初就是想测试Hermes到底好不好用,之前一直在用openclaw,不过这个项目给我最大的感觉就是Hermes确实挺好用,轻量、快、聪明!
还有就是toutiao号我不怎么用,万一Hermes不好用把我这个号玩废了也不怕。
更重要的就是一个人做自媒体,最痛苦的不是写不出来,而是时间不够用。
4个时间窗口要填内容。手动选题2小时,写稿2-3小时,配图1小时,发布+看数据半小时。一天5小时搭进去了。
等于一个人干了一家报社的活。跑新闻的记者、写稿的编辑、画图的美编、上版的发行、看报表的数据分析,全是你。
你可能想说:找个大模型比如ChatGPT帮忙写不就行了?
不行。
ChatGPT帮你写个草稿,你还得手动改稿降AI味、手动找选题、手动配图、手动登录后台发布。省了写稿的时间,其他环节一个都没少。这叫半自动,不是自动化。
我想试试另一种东西:选题不用我找,文章不用我写,配图不用我做,发不用我点,数据不用我看。人基本不碰。
5个小时降到5分钟。这才是真正的自动化。
怎么做的?拆开给你看。
5个Agent,像报社流水线
我的系统没有用一个大模型干所有事。而是拆成了5个专职Agent,各管一段,像报社的流水线:
- Scout(侦察兵):负责选题,像到处跑新闻的记者
- Writer(写手):负责写稿、改稿、配图,像编辑部的文字编辑+美编
- Publisher(发行):负责发到头条,像发行部门的排版上版
- Feedback(数据分析师):负责回收阅读数据,像看销量报表的分析师
- Orchestrator(总编):负责调度谁先干谁后干,像排版的总编
Agent之间怎么通信?文件夹。
我没上LangGraph、CrewAI、AutoGen这些框架,也没用数据库。就是文件系统当队列,JSON文件当协议。
```
queue/
├── pending/ ← 等发布的内容在这里
│ ├── 07:00/ ← 早高峰slot
│ │ ├── 20260505-053513-article.md
│ │ └── 20260505-053513-article.meta.json
│ ├── 12:00/ ...
│ ├── 18:00/ ...
│ └── 21:00/ ...
├── published/ ← 发布成功移过来
└── failed/ ← 失败的放这里
每个slot就是一个时间窗口。`.md`文件是文章内容,`.meta.json`是元数据——标题、分数、配图路径、审校分数,全记在里面。
为什么不用数据库?
因为图方便,这个实验项目我觉得文件系统就是最好的队列。Scout写完一个JSON文件,Writer直接读它。Publisher发布成功就把文件从pending/移到published/。
整个数据流就是文件的流转。不需要MySQL,不需要Redis,不需要任何中间件。
你拿到手的,就是5个subagent的Python脚本 + 1个bash调度脚本 + crontab。总共6693行代码。
如果项目变大,让Hermes再部署个数据库就行。
好了,分工搞清楚了。
但选题才是灵魂——选题不对,写得再好也没人看。
## Scout:138个信息源,6小时扫完,它替你刷完了
选题最烦的是信息过载。每天几百条技术新闻,人工根本刷不过来。
你每天刷多久推特?半小时?一小时?
我的Scout每天自动扫描138个信息源,每次发布前跑一次。覆盖5种来源:
* Twitter KOL 48个账号(@karpathy等大V)
* RSS订阅 49个源(Hacker News、TechCrunch、官方博客)
* GitHub Trending 28个仓库
* Reddit 13个板块
* Web搜索补充
缓存里常驻50个候选选题。但50个显然不能全写。怎么选?靠评分。
评分公式长这样:
总分 = 源质量^1.3 × 0.22 + 传播潜力 × 0.25 + 新鲜度 × 100 × 0.20
三个维度,每个都有门道。
**源质量——不是所有信息源生来平等。**Twitter上经常爆料的大V权重是35,普通RSS订阅源才15。
关键在`^1.3`这个指数。源质量越高,分数被放大得越狠。一个35分的大V和一个15分的RSS,差距不是20分,是被指数放大后的差距。大V说的东西天然更值得关注,公式里直接体现了这一点。
**新鲜度——抓热点要趁早。**6小时以内的新闻标记为「爆发期」加分,24-48小时的「热议期」略加,超过48小时的「已过期」扣分。一个刚爆出的漏洞(1小时),新鲜度满分。一个两天前的旧闻,直接减分。
**爆款词库——系统自己学会的。**有个叫hit\_library的文件,记录过去表现好的关键词。当前记录的关键词有AI、大模型、agent等。下次选题时,命中这些词的候选会额外加分。
这意味着什么?系统已经在自己摸索"什么方向该多写"了。不是我在告诉它写什么,是数据在告诉它。
选完题后,每个候选带上这些信息:
{
"topic": "Microsoft Edge stores all passwords in clear text",
"score": 49,
"source": "Hacker News Frontpage",
"freshness_label": "爆发期",
"age_hours": 1.0
}
分数、来源、新鲜度一目了然。Writer直接拿这个写。
打个比方:Scout像一个每天刷5个小时推特的技术编辑,刷完能告诉你「今天这5个话题最值得写」。而你随时可以看它选的怎么样。
选题有了,写作才是大头。也是这个系统真正拉开差距的地方。
## Writer:7个阶段,每篇文章都要"考试及格"才放行
大多数人用AI写文章的方式:把需求丢给大模型,拿到结果,稍微改改,发布。
问题是什么?AI味太重。
「值得注意的是」「总的来说」「我们不禁要问」——这些词一出现,读者就知道是AI写的。平台的算法也会检测AI内容,严重的直接限流。
所以我的Writer不是一个阶段,是七个。
**第一站:抓原文。**从选题里的URL抓取原始报道内容。有本地缓存,同一个URL不重复抓。
**第二站:LLM生成初稿。**调GLM API写初稿。我用的是国产模型glm-5.1。我觉得挺好用。
**第三站:AI腔审校。**这是我花时间最多的一步。
系统维护了100多条正则规则,分6大类检测AI腔:
* 套话连篇(9条规则):检测「在当今时代」「随着XX的发展」「综上所述」——检测到直接砍
* AI句式(4条规则):检测「不仅…而且…」「一方面…另一方面…」——拆成短句
* 书面词汇(10条规则):检测「显著提升」「充分利用」「旨在」「致力于」——换成口语
* 结构机械:检测「首先…其次…最后…」——打散成自然段落
* 态度中立(3条规则):检测「具体取决于实际情况」「各有优劣」——逼它表态
* 细节缺失(6条规则):检测「许多」「一些」「大量」——必须给具体数字
每发现一个问题,按严重程度扣分。严重扣8分,中等扣5分,轻微扣2分。满分100。
这一步的分数通常在90分以上。AI写的初稿大概30-50分,经过审校能拉到90分。
**第四站:批评-修订循环。**光靠正则不够。让另一个LLM当「评委」打分,低于70就打回去重写,最多改2轮。
今天的实际评分轨迹:第一轮65分,改完第二轮92分。另一篇72分改到88分。改一轮就能从不及格到优秀。
为什么这步重要?大模型一次出稿,质量全看运气。而我的系统是**考试及格才放行,不及格就打回重写**。每篇文章至少经过两轮审校。
**第五站:排版。**中英文之间加空格,段落之间加空行,自动加hashtag标签。
**第六站:标题优化。**只对长文做。生成3个候选标题,分别打分,选分数最高的。
**第七站:配图。**两条路径:一条是调用大模型生图API生成插图,另一条是用HTML模板渲染信息图。我预设了HTML模版,版式统一,虽然不如生图API的那么好看,但是胜在不要钱~😄
想象一个编辑部:实习生写初稿,文字编辑去AI腔,主编审稿打分,打回来就改,改完排版,版式编辑起标题,美编配图。
我的Writer就是这个编辑部。只不过里面全是代码,没有人在。
每个阶段的质量数据会保存到meta.json:
{
"proofread_score": 93,
"critique_scores": [65, 92],
"revised": true,
"title_score": 60,
"word_count": 564
}
一句话总结Writer:**不是调一次API就出稿,而是像一个真正的编辑部——7道工序,每道都有质检。**
文章写好了,怎么发?这是最坑的部分。
## Publisher:没有API,就让它操作浏览器
头条没有发布API。没有。
这意味着什么?如果你想自动发布,不能用接口调一下就完事。
也就是我要解决浏览器自动化的问题,让AI像人一样打开浏览器,点按钮、输文字、提交。
为什么这步值得做?
因为发布是所有自媒体人最无聊的环节。登录后台、复制标题、粘贴正文、上传图片、选分类、点发布,一篇文章至少3分钟。一天13篇,光发布就快40分钟。
我的Publisher用Playwright CLI控制一个真实的Chromium浏览器,模拟人的操作。听着简单,坑一个接一个:
**坑1:服务器没显示器。**代码跑在腾讯云服务器上,没有物理屏幕。浏览器启动就报错。解决方案是装一个叫Xvfb的虚拟显示器——它假装有一个屏幕,让浏览器以为在正常环境里运行。一行命令:`Xvfb :99`。
**坑2:草稿箱会爆。**头条的草稿箱上限是多少我也不知道,但是我的草稿箱超过了250篇移动端就不同步。我写了一个自动清理逻辑,每次发布后检查草稿箱数量,超过100篇就自动删旧的。
**坑3:Cookie会过期。**浏览器登录状态靠Cookie维持,过期了就发布不了。Cookie文件存在本地,过期了需要手动更新一次。
发布到公开平台,安全是底线。
**所有内容先进草稿箱,绝不直接发布。**内容就绪后通知Discord和微信,双保险。cron环境里`--publish`参数被代码直接禁用。哪怕配置写错了也不会直接发出去。
有个重要对比:有些第三方发布工具会调API直发,容易被平台检测到机器操作,轻则限流重则封号。我的方案是真实浏览器操作+草稿箱中转+人工审批,和手动操作一模一样,**100%安全**。
像一个守规矩的发行员。你告诉他「只许放草稿箱」,他就真的只放草稿箱,哪怕凌晨3点没人看着。
发完了就不管了?不行。还有个数据飞轮,让系统自己变强。
## Feedback:系统自己学会了"AI方向该多写"
发完就不管了?那AI永远不会进步。它不知道什么选题有人看,什么标题能吸引点击。
所以我加了个反馈飞轮。
**第一步:回收数据。**Feedback模块通过Puppeteer自动登录头条后台,抓取每篇文章的阅读数、评论数、分享数。
**第二步:建爆款词库。**所有数据写入results.tsv的同时,更新一个叫hit\_library.json的文件。记录哪些关键词、什么类型的标题、什么方向的选题表现好。
当前的hit\_library记录了25篇有效数据:hit rate 4%,平均阅读60.9。
**第三步:反哺选题。**下次Scout选题时,命中hit\_library里的关键词(AI、大模型、agent)会额外加分。
关键不在于数据好不好看,而在于这个过程是自动的。不是我在分析"最近AI方向数据不错,多写几篇",是系统自己从数据里发现了这个规律,然后自动调整选题权重。
说白了就是系统自己摸索出了「AI方向最近数据好,多写」这个经验。**不是人教它的,是数据教它的。**
**第四步:策略进化。**Feedback还会分析数据趋势,往策略文件program.md里追加AI建议。比如「对比型标题最近表现好,建议多用」。
飞轮转起来了:选题→写作→发布→数据→优化选题。每转一圈,系统就聪明一点。
但你得能看到它在转。
## Dashboard:从盲跑到可视化
做这个系统开始的两天,我完全是盲跑。
cron任务挂了?不知道。scout重试3次全失败?不知道。18:00的slot是空的?事后翻日志才发现。
直到有一天我看到cron.log里记录着:
⚠️ Scout 3次重试均失败 [07:00],发送告警通知
07:00的slot,Scout因为信息源数据不够,重试了3次全失败。整个早高峰一篇内容都没有。而我完全不知道这件事。
这就像开车没有仪表盘。你不知道油还剩多少,不知道引擎有没有问题,直到车熄火了才发现。
所以花了2个小时做了个系统监控Dashboard。
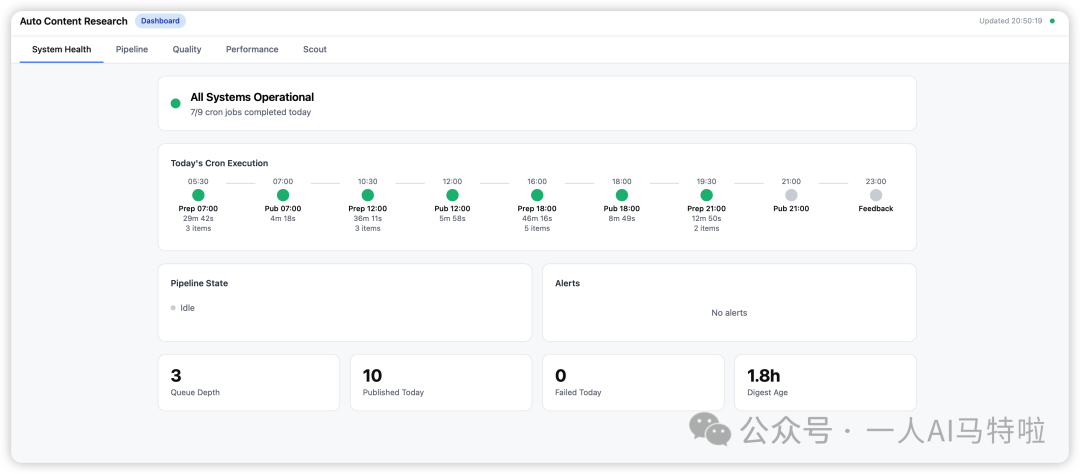
5个Tab,每个解决一个具体的监控问题:
**System Health**——今天的9个cron任务,用一条时间线展示。05:30准备07:00的内容,耗时16分钟,成功。07:00发布,耗时4分钟,成功。16:00准备18:00的内容,耗时22分钟……哪个挂了、哪个超时,一眼看出来。
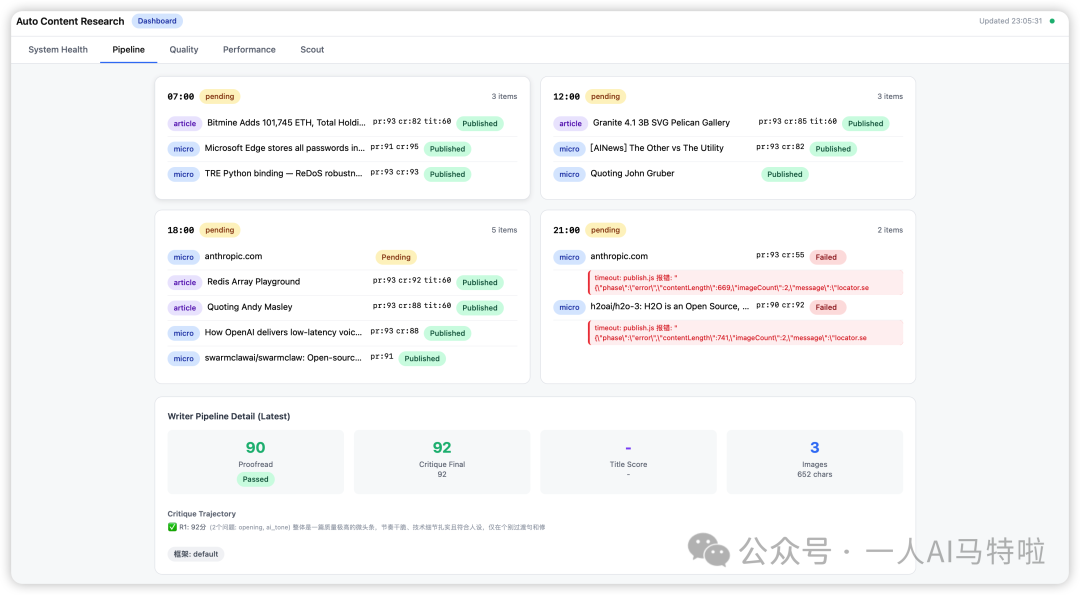
**Pipeline**——4个slot各自的状态。每篇文章带着审校分数93、critique轨迹65→92、标题分数60。哪篇内容质量高、哪篇被改过,清清楚楚。比如下图显示今天21点的推送就因为超时失败了,我还要去排查
**Quality**——质量分数按天的变化曲线。方向分布饼图(热点新闻vs实用教程vs创业,目标是40/35/25)。新鲜度分布。
**Performance**——阅读量趋势、按时间段对比、按方向对比。
**Scout**——候选选题的分数分布、信息源分布。
Dashboard怎么做出来的?超简单。
后端用Python标准库的HTTPServer。没上Flask、没上FastAPI,1125行代码8个API。前端一个HTML文件,Tailwind + Chart.js,742行。数据全是读文件:解析cron.log拿cron状态,读meta.json拿质量分数,读results.tsv拿阅读数据。
没有数据库。没有Redis。没有前端框架。没有Node.js。
从「盲人开车」到「有了仪表盘」。不需要一直盯着,扫一眼就知道系统健康不健康。
## 你也能搭一个
你可能觉得这玩意儿很复杂。拆开看其实就这些:
5个Python脚本 + 1个bash调度脚本 + 1个Dashboard HTML + crontab。总共6693行代码。
不需要LangGraph、CrewAI、AutoGen。不需要数据库。不需要前端框架。核心技术就三样:Python、文件系统、cron。
**你手搓一个最小可用版,3个脚本500行代码就够了。**
第一步:装Hermes Agent。
Hermes Agent是一个开源的AI Agent框架(类似Claude Code),支持skills、cron、webhook等能力。我用的版本是v0.12.0。
hermes setup # 交互式配置向导,配置API key和模型
第二步:写几个脚本。每个Agent的核心模式都一样:
# 1. 读输入(从文件)
# 2. 调LLM(用OpenAI兼容接口)
# 3. 写输出(写到文件系统)
input_data = read_json("queue/pending/scout_results.json")
result = llm_call(prompt, input_data)
write_json(f"queue/pending/{slot}/xxx.meta.json", result)
先写最小可用版:一个脚本做选题,一个脚本调API写文章,一个脚本发布。三个脚本500行左右就能跑。
第三步:用文件命名约定把脚本串起来。
Scout写 `scout_results.json`→ Writer读它,输出 `YYYYMMDD-HHMMSS-{type}.md`+ `.meta.json`→ Publisher读这两个文件,成功后移到 `published/`。
文件名就是Agent之间的「协议」。不需要消息队列,不需要RPC,不需要任何中间件。
第四步:加cron定时任务。
# crontab -e 加这几行就行:
30 5 * * * /path/cron-pipeline.sh prepare 07:00 1 2 # 早高峰1文+2微
30 10 * * * /path/cron-pipeline.sh prepare 12:00 1 2 # 午休1文+2微
0 16 * * * /path/cron-pipeline.sh prepare 18:00 2 3 # 晚高峰2文+3微
30 19 * * * /path/cron-pipeline.sh prepare 21:00 0 2 # 睡前0文+2微
“`
第五步:加监控。让Hermes review,然后做个Dashboard。
总共大概1-2天就能做出来。像搭积木——每块积木本身很简单(读文件、调API、写文件),关键是知道先搭哪块、怎么连接。
回到最开始
开头我说:每天13篇内容,我需要做的确认选题和发布。
这不是在吹牛。这个系统已经跑起来了。选题有Scout盯着138个信息源,写作有Writer的7道质检关卡,发布有Publisher的浏览器自动化,数据有Feedback的飞轮反哺。
每天5小时的工作量,降到了5分钟。
架构全公开了。核心模式三个字——读、算、写。每个Agent干的就是这三件事。
一个人加几个AI Agent,真能顶一个小型内容团队。
关键是动手。
彩蛋
千万不要从头造轮子,要站在巨人的肩膀上,善用工具。你想做的事情或者踩的坑,大概率别人都遇到过或者做出来过类似的东西。
这个项目本质上是对工具的测试和整合,比如Hermes,比如@花叔那一套好用的skill, 比如baoyu infographic skill, 比如Playwright CLI, 去搜一搜,然后动手,根据自己的需求让智能体去修改整合,直到你满意为止。
免责声明:
本文所载程序、技术方法仅面向合法合规的安全研究与教学场景,旨在提升网络安全防护能力,具有明确的技术研究属性。
任何单位或个人未经授权,将本文内容用于攻击、破坏等非法用途的,由此引发的全部法律责任、民事赔偿及连带责任,均由行为人独立承担,本站不承担任何连带责任。
本站内容均为技术交流与知识分享目的发布,若存在版权侵权或其他异议,请通过邮件联系处理,具体联系方式可点击页面上方的联系我。
本文转载自:一人AI马特啦 一人AI马特啦 一人AI马特啦《我用Hermes通过5个Agent搭了一条内容自动生产线, 现在每天能发13篇, 极大的提高了创效率》

版权声明
本站仅做备份收录,仅供研究与教学参考之用。
读者将信息用于其他用途的,全部法律及连带责任由读者自行承担,本站不承担任何责任。







评论