

文章总结: 本文是AI与AI安全系列第三篇,重点解析Transformer架构原理及其在LLM中的应用。文章详细介绍了注意力机制、多头注意力计算过程,以及LLM从词元输入到文本生成的完整工作流程。作者通过通俗比喻解释技术概念,并提供了原始论文参考链接,帮助读者建立AI安全领域的基础认知框架。 综合评分: 72 文章分类: AI安全,技术标准,安全培训,WEB安全,其他
AI与AI安全:Transformer原理初步①文字版
原创
AugustTheodor AugustTheodor
重生之成为赛博女保安
2026年5月7日 10:17 吉林
在小说阅读器读本章
去阅读
前注
本篇是原定的AI与AI安全系列的第一篇。当然后面由于各种原因,一个是AI投毒事件,一个是我想试试讲课,被拖到第三篇。
这篇和https://www.bilibili.com/video/BV183ojBuE1Y(同样的,点击阅读原文)配套,同时如果两边的描述有不一致,介于两者创作的时间差——尽量以视频为准(当然鉴于直播时要把讲的部分串起来,所以本文中的很多其他原理部分就没有涉及)。
以下原文:
写在系列开始之前
首先,由于笔者苯人也不怎么懂。所以在这个系列里我们不太可能进行数学上的探讨。
本系列中所有关于原理的解释,都仅致力于让读者简单理解:
①LLM中的部分原理
②AI行业的一些术语
③AI衍生的应用方向的实现方式(MCP、Skill、Agent、龙虾…)
④AI安全
所以在准确度和专业度上可能会差强人意,请各位读者谅解。
这个系列随着AI的蓬勃发展(现已火热进行中)会不断更新。
1 基础背景小知识
1.1 基础名词解释
LLM:Large Language Model,大语言模型,可以简单理解为文生文模型。
Transformer:一个架构,当前广泛应用于模型训练中。
卷积:在AI中,卷积是指对一个“窗口”内的数据做加权求和。当作一种数学运算就行。
Embdding(嵌入):在AI中是将离散数据转换为连续向量的技术(etc.“我”->[1,3,2,1…..]),也就是用数学上一个可以量化对比的数据反映原始数据。
Tokenizer(分词器):简单来说就是将一段话切成对应词元ID的数组(etc.“我爱安全”->[123,456,789])。
Sampling(采样):对模型的运行结果进行一定处理(比如添加一个小随机数),然后根据处理后的结果选出对应输出。
残差连接:一种将输入与输出直接相加的技术(请想象两条曲线的Y轴相加),这个技术旨在保留训练数据的梯度。
梯度:可以简单理解为“某一个值的变化速度”,也可以理解成“导数的斜率”。总得来说,在LLM中这个值不能太大(梯度爆炸)也不能太小(梯度消失)。
反向传播(BP):在AI训练中被使用的一种方法,它能够根据误差向回推算每一层的梯度,进而对每一层进行校准。
归一化:将一系列参数进行放缩令其和为1。
Hidden State(隐藏状态):
lm_head(输出头):一个函数。输入隐藏状态,得到词表得分(Logits)。简单来说,输入一个向量,得到一个可能对应的词元的列表。
FFN(Feed-Forward Network,前馈网络):FFN是一个广泛应用于所有深度学习框架中的神经网络,它会对输入进行一系列变换然后输出。在目前情况下我们可以简单理解它为一种运算单元。
1.2 AI的工作原理
数学建模。
Yes It Is!AI的原理就是通过一系列训练让所有输入->输出拟合训练集的输入->输出。
天气是可以预测的,情绪是可以预演的!对这个数学的世界绝望了^ ^!
1.3 LLM的工作原理
这句话应该会贯彻本系列的所有文章:当前绝大多数(其实可以说是所有)LLM的工作方式是“续写”,也就是根据当前所有输入,预测下一个输出。所谓的skill、agent等模式实际上都是在此基础上的变体。
1.4 Transformer背景小知识
很难想象,Transformer这个架构仅在九年前被提出。在2017年,一篇由谷歌研究员发表的原文仅有11页(去掉引用只有9页)的论文《Attention Is All You Need》提出了一个全新的架构Transformer,它与传统模型RNN或CNN的不同在于,完全基于注意力机制,能够以相对极高的效率处理大量文本。
感兴趣的读者可以通过传送门拜读原文:
https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
需要注意的是,当下几乎所有主流LLM都基于Transformer架构。这也是我们在学习AI安全之前要先了解这个架构的原因。
1.5 Encoder/Decoder
在AI领域中,我们可以简单地将Encoder理解为“将输入(文字、图)拆解成抽象表示(向量)”的模块。与此相对的,Decoder则可以称为“以抽象表示为上下文,生成输出”的模块。
这两个模块最初发明于翻译类大模型中,而在当代以“续写”为核心主流LLM中通常只有Decoder。
2 注意力(Attention)
2.1 背景,名词解释
简单说说,注意这里不涉及任何数学问题,不然主播现在应该在北大而不是加里敦。
首先,注意力机制在2014年还是被谷歌的研究员提出。
https://proceedings.neurips.cc/paper_files/paper/2014/file/3e456b31302cf8210edd4029292a40ad-Paper.pdf
当然,这个机制在后续经过了非常多迭代发展,并非完全是14年提到的样子。这里给出的文章仅供参考。
需要注意的是,注意力机制有很多变体。而Transformer中使用的自注意力(Self-Attention)机制则是其中之一,除此之外,还有传统注意力(Cross-Attention)、稀疏注意力等。
3 Attention
3.1 简单的原理
先使用人话解释一下。注意,这里全部都是笔者个人理解,不是实际上的精确原理。
In practice, we compute the attention function on a set of queries simultaneously, packed together
into a matrix Q. The keys and values are also packed together into matrices K and V .
首先,对于每个输入source(s),存在查询Q、键值对K和V。Q意为当前s的需求(要找什么),K意为当前s拥有的身份(是什么),V意为当前s可以提供的内容(带有什么)。
对每个输入,经过这样的拆分后互相运算,得到当前输入的融合后矩阵Attention(Q,K,V)。
3.2 简单的计算过程
需要一些小小的离散数学。当然不懂也没事,知道个大概就好。
我们假设输入文本为S。
S=[s1...sn]
其中,sn代表一个词元。由于LLM会使用一个不定维数的向量表示词元,所以实际上S是一个向量数组(矩阵)。
对于每一个Transformer层,有三个矩阵Wq、Wk、Wv。当文本输入后,对于每个词元sn,得到`Qn=Sn*Wq、`Kn=Sn*Wk、`Vn=Sn*Wv。
然后得到S的整个Q=[`Q1...`Qn],以此类推。
然后再经历一系列运算,这里摘抄原文的公式表示:
Attention(Q,K,V)=[`s1...`sn]
当然这里仍然可以再用人话表示一下(具体请看视频),矩阵A*矩阵A`转置*矩阵A``/标量=矩阵A```=>它的输入和输出行列数是相同的,这也是它能连续经过N个同样的层的原因。
3.3 Multi-Head Attention(多头注意力)
正如上文所言,在LLM中一个词元会被视为一个有n个维度的向量。在此基础上我们自然可以想到:当维度过多时,对其进行运算的精度损失会变多——就像一个人如果同时关注很多事情,那么TA的注意力肯定也会被分散削减。
在多头注意力中,输入的维度会被分割成多个头分别单独处理(至于怎么分,不是我们的重点,可以跳过),以改善上面提到的精度损失问题。
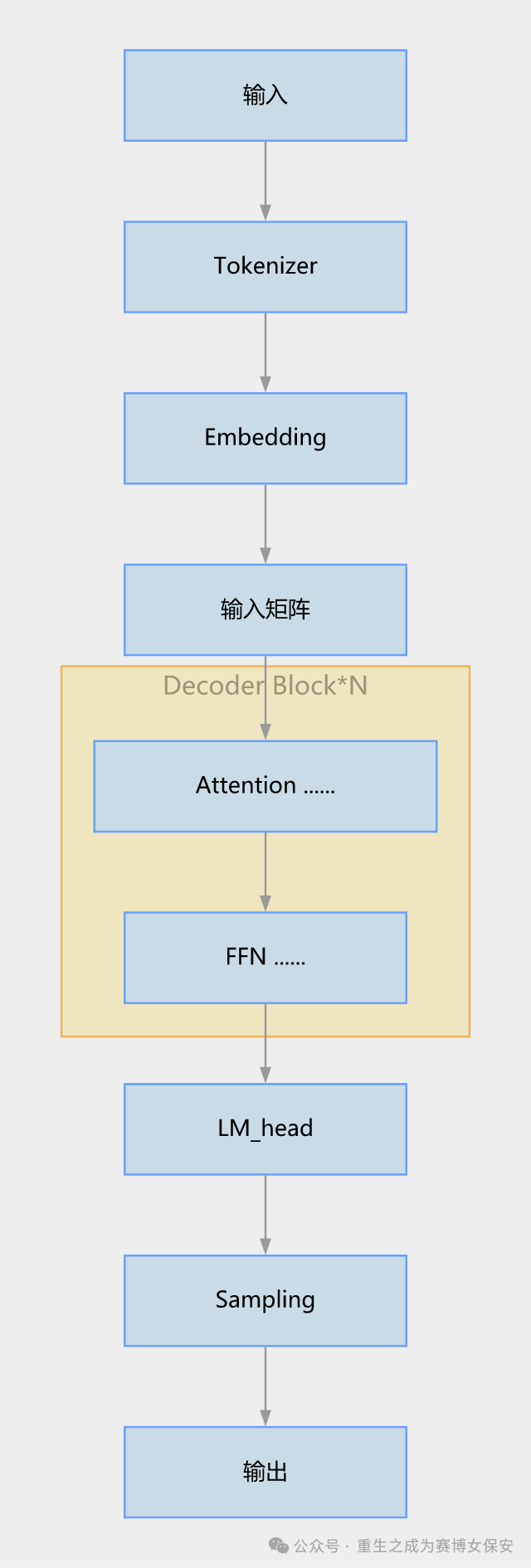
4 Transformer LLM构造(以下为直播补充部分)
4.1 一个词元是怎么进入大模型的?
4.2 运算后的向量是怎么还原成一个词的?
4.3 LLM运作流程
. . . * . * 🌟 * . * . . .
本文为AI与AI安全系列第 3 篇。
喜欢这个系列的读者可以关注一下我的公众号。咱们之后见。
免责声明:
本文所载程序、技术方法仅面向合法合规的安全研究与教学场景,旨在提升网络安全防护能力,具有明确的技术研究属性。
任何单位或个人未经授权,将本文内容用于攻击、破坏等非法用途的,由此引发的全部法律责任、民事赔偿及连带责任,均由行为人独立承担,本站不承担任何连带责任。
本站内容均为技术交流与知识分享目的发布,若存在版权侵权或其他异议,请通过邮件联系处理,具体联系方式可点击页面上方的联系我。
本文转载自:重生之成为赛博女保安 AugustTheodor AugustTheodor《AI与AI安全:Transformer原理初步①文字版》

版权声明
本站仅做备份收录,仅供研究与教学参考之用。
读者将信息用于其他用途的,全部法律及连带责任由读者自行承担,本站不承担任何责任。







评论